
filebeat와 ELK스택을 이용해 Nginx의 로그를 가볍게 연동만 하는 작업을 했었다.
그와 더불어 Django의 로그또한 연동을 해보고 싶었는데, 도커의 볼륨 컨테이너 등에 대한 이해도가 현저히 떨어졌기때문에 연동하기가 더 쉽지 않았다.
또한 페이지가 너무 복잡해 키바나로 대쉬보드 조차 만들어보지 못했다. 진짜 딱 연동만 해봤었다.
다른 테스크 하면서 시간이 날때마다 틈틈히 해서 드디어 연동과 대쉬보드 만드는 법을 알아냈다.
추가로 도커에대한 이해도 또한 같이 올라간거 같아서 기분이 좋다.
https://kingmusung.tistory.com/25
백엔드 로그를 찍어보자
api에 간단한 로그를 찍어보자! elk를 연동하던중.. 프론트엔드 쪽 로그가 아닌 백엔드쪽 로그를 만들어서 elasticsearch에 보내보고 싶어서 시작을 하였지만, 아래 방식처럼 찍으면 elasticsearch에서 인
kingmusung.tistory.com
Nginx의 로그와 Django의 access.log, error.log 만으로는 내가 원하는 결과가 출력이 안되어서 직접 만들어서 연동을 해보겠다.
위 링크는 전에 가볍게 로그를 찍는 법만 적어놓았다.
https://kingmusung.tistory.com/23
위 글은 우여곡절 끝에 기초세팅만 해놓은 상태이고, Nginx 로그만 연동 및 기본적인 세팅만 되어있습니다.
🔥기본세팅
settings.py
LOGGING = {
'version': 1,
'disable_existing_loggers': False, # 디폴트 : True, 장고의 디폴트 로그 설정을 대체. / False : 장고의 디폴트 로그 설정의 전부 또는 일부를 다시 정의
'formatters': { # message 출력 포맷 형식
'verbose': {
'format': "[%(asctime)s] %(levelname)s [%(name)s:%(lineno)s] %(message)s",
'datefmt': "%d/%b/%Y %H:%M:%S"
},
'simple': {
'format': '%(levelname)s %(message)s'
},
},
'handlers': {
'member_file': {
'level': 'INFO',
'class': "logging.FileHandler",
'filename': os.path.join(BASE_DIR, 'logs') + "/backend.log"
},
'calendar_file': {
'level': 'INFO',
'class': 'logging.FileHandler',
'filename': os.path.join(BASE_DIR, 'logs') + "/backend.log"
},
'diary_file': {
'level': 'INFO',
'class': 'logging.FileHandler',
'filename': os.path.join(BASE_DIR, 'logs') + "/backend.log"
},
'static_file': {
'level': 'INFO',
'class': 'logging.FileHandler',
'filename': os.path.join(BASE_DIR, 'logs') + "/backend.log"
},
},
'loggers': {
'member': {
'handlers': ['member_file'],
'propagate': True,
'level': 'INFO',
},
'harucalendar': {
'handlers': ['calendar_file'],
'propagate': True,
'level': 'INFO',
},
'diary': {
'handlers': ['diary_file'],
'propagate': True,
'level': 'INFO',
},
'static': {
'handlers': ['static_file'],
'propagate': True,
'level': 'INFO',
},
}
}
요약하자면, handler에 어떤 형식의 핸들러를 사용할지 정의를 해주고, 로그를 저장 할 디렉터리와 로그레벨을 설정해주었다. 사실 지금 보면 같은 디렉터리에 같은 파일에 로그를 저장할 의도였으면 하나의 핸들러만 정의 했어도 될거같다.
(초기에는 각각 로그파일로 관리하기위한 의도였음.)
그 아래 logger에는 어떤 handler를 사용할지 정의해주고 로그레벨을 기록해주면 된다.
Views.py 의 코드 일부분
logger.info(f'INFO {client_ip} {current_time} GET /calendars 200 calendar is inquired')logger.info(f'INFO {client_ip} {current_time} POST /calendars 200 calendar Stickers are saved')logger.warning(f'WARNING {client_ip} {current_time} POST api/v1/diaries//DiriesPost 400 {calendar_serializer.errors}')
로그를 찍을때도 일관적인 형식을 가지고 찍어야한다는걸 깨달았다. 나의 경우에는
로그레벨, 아이피, 시간, 요청방식, url, 상태코드, 메시지 순서로 로그를 찍었다.
backend.log
INFO 127.0.0.1 2024-02-04 05:09:01 POST /members 200 login success
INFO 127.0.0.1 2024-02-04 05:23:20 POST /members 200 login success
INFO 127.0.0.1 2024-02-04 05:23:39 POST /members 200 login success
INFO 127.0.0.1 2024-02-04 05:23:39 POST /members 200 login success
api요청을 하면 이런식으로 로그파일에 로그가 찍히게 된다.
🔥 Logstash setting.
pipline.yml
input {
file {
path => "/logs/backend.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{LOGLEVEL:loglevel} %{IP:ip_address}
%{TIMESTAMP_ISO8601:timestamp} %{WORD:http_method} %{URIPATH:http_path} %{NUMBER:http_status} %{GREEDYDATA:log_message}" }
}
date {
match => [ "timestamp", "ISO8601" ]
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "member-%{+YYYY.MM.dd}"
user => "elastic"
password => "changeme"
}
stdout { codec => rubydebug }
}
input {
file {
path => "/logs/backend.log"
start_position => "beginning"
}
}
path 이 부분은 logstash 컨테이너 내부에 /logs/backend.log 경로에 있는 backend.log파일을 입력값으로 넣겠다는말이다.
내 로컬에 있는 로그파일이 컨테이너 내부로 그냥 마운트 되지는 않을것이다.
docker-compose.yml(logstash 부분, 불필요한 코드는 생략)
logstash:
#전부 생략
volumes:
- ./haruProject/logs/:/logs/
#전부 생략
로그스테쉬의 볼륨을 설정을 해줌으로 로컬에 있던 로그파일이 logstash의 컨테이너 내부 경로로 마운트되게 해준다.
./haruProject/logs/ 에 있는 모든 파일을, 컨테이너 내부 logs라는 디렉터리 하위에 위치하겠다는 말.
./ 이부분은 docker-compose.yml 이 위치한 현제 경로를 말 하는거임.
즉 haruProject는 docker-compose.yml이랑 같은 위치에 있다는말
filter {
grok {
match => { "message" => "%{LOGLEVEL:loglevel} %{IP:ip_address} %{TIMESTAMP_ISO8601:timestamp} %{WORD:http_method} %{URIPATH:http_path} %{NUMBER:http_status} %{GREEDYDATA:log_message}" }
}
date {
match => [ "timestamp", "ISO8601" ]
}
}
필터부분인데 이 부분이 너무 어려웠었다.
일단 Grok부터 살펴보면
Grok이란?
사용자가 정의한 패턴을 사용하여 텍스트를 추출, 구조화를 하는 역할을한다.
logger.info(f'INFO {client_ip} {current_time} GET /calendars 200 calendar is inquired')"%{LOGLEVEL:loglevel} %{IP:ip_address} %{TIMESTAMP_ISO8601:timestamp} %{WORD:http_method} %{URIPATH:http_path} %{NUMBER:http_status} %{GREEDYDATA:log_message}" }
내가 정의한 로그 형식과, grok필터에서 정의한 부분을 비교해보면 한가지 패턴을 찾을 수 있다.
loglevel -> INFO, ip_address -> {client_ip}, timestamp -> {current_time}, http_method -> GET, http_path -> /calendar,
http_status -> 200, log_message-> calendar is required
이런식으로 매치가 될것이다.
LOGLEVEL, IP TIMESTAMP_IS08601 처럼 대문자로 되어진 부분은 엘라스틱 서치가 인식할 수 있는 정해진 변수명이므로 임의로 바꾸면 안된다.
loglevel, ip_address, timestamp등 소문자로 된 부분은 사용자가 정의 할 수 있는 변수명이다 이 변수명은 나중에 시각화를 하는 과정에서 우리가 원하는 정보를 볼 수 있게 해주는 변수명이다.
(위 사진은 지금까지 작업을 거친 후 키바나로 대쉬보드를 생성 했을때 볼 수 있는 화면중 일부이다. 이해를 위해 첨부했다.)
🏝️ Elastic Search
이제 기본적인 설정을 하였으니, 로그가 잘 넘어왔는지 확인을 해보자
위 작업을 거친 후 토커컴포즈를 이용하여 컨테이너를 실행시켜준다
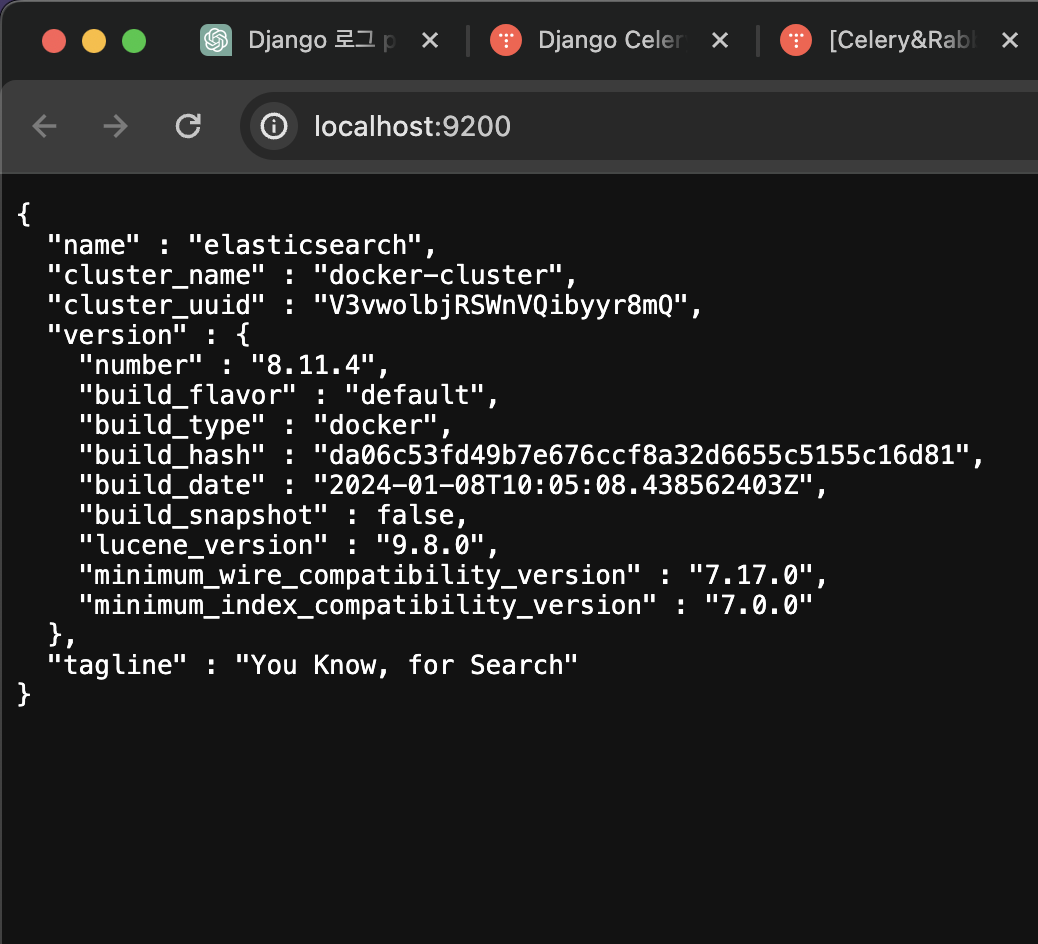
컨테이너에서 ElasticSearch의 포트번호로 (http://localhost:9200/) 접속 후 위와 같은 화면이 뜨면 잘 실행이 되고있는것이다.
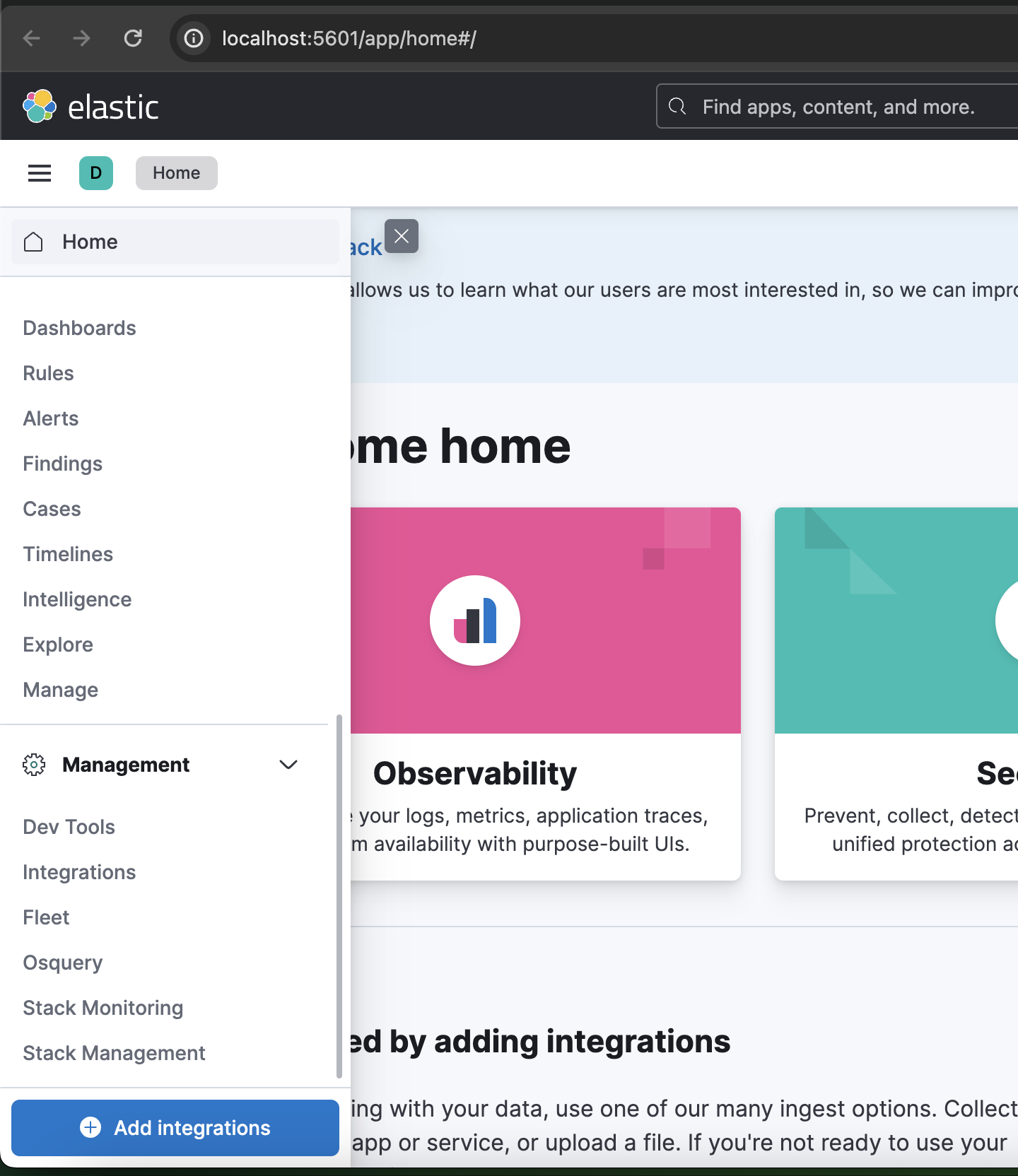
그 후 키바나의 포트번호로(http://localhost:5601/app/home#/) 들어가게 되면 위와같은 화면이 나오게 되고.
좌측 맨 하단에 Stack Management -> Index Management 까지 들어가주면
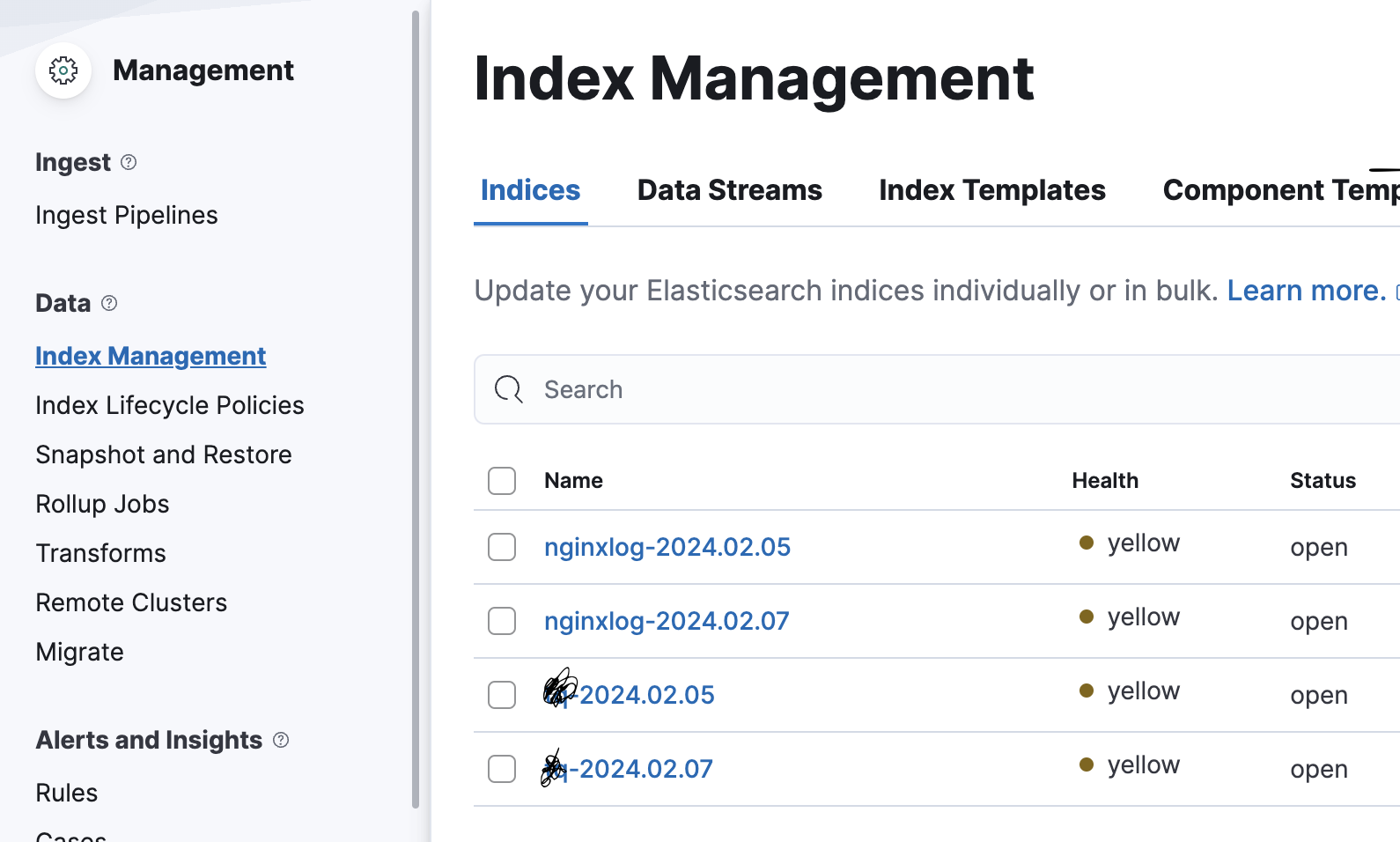
위 사진처럼 로그들이 넘어오는걸 확인 할 수 있다.
만약 아무것도 없다면,
✅ Docker 볼륨부분을 잘 확인해 보는걸 추천한다, 필자의 경우는 마운트를 잘못시켜서 로그가 잘 안넘어왔었다.
✅ Logstash의 필터부분에 표현식이 맞는지 검토를 해보는걸 추천한다.
🏖️ Kibana DashBoard
인덱스가 넘어오는걸 확인을 하였다면. 아까처럼 좌측 하단이 아닌 좌측 상단에 보면 Dashboard라는 항목이 보이는데 클릭을 해준다.
그 후 create data view 를 클릭해주고.
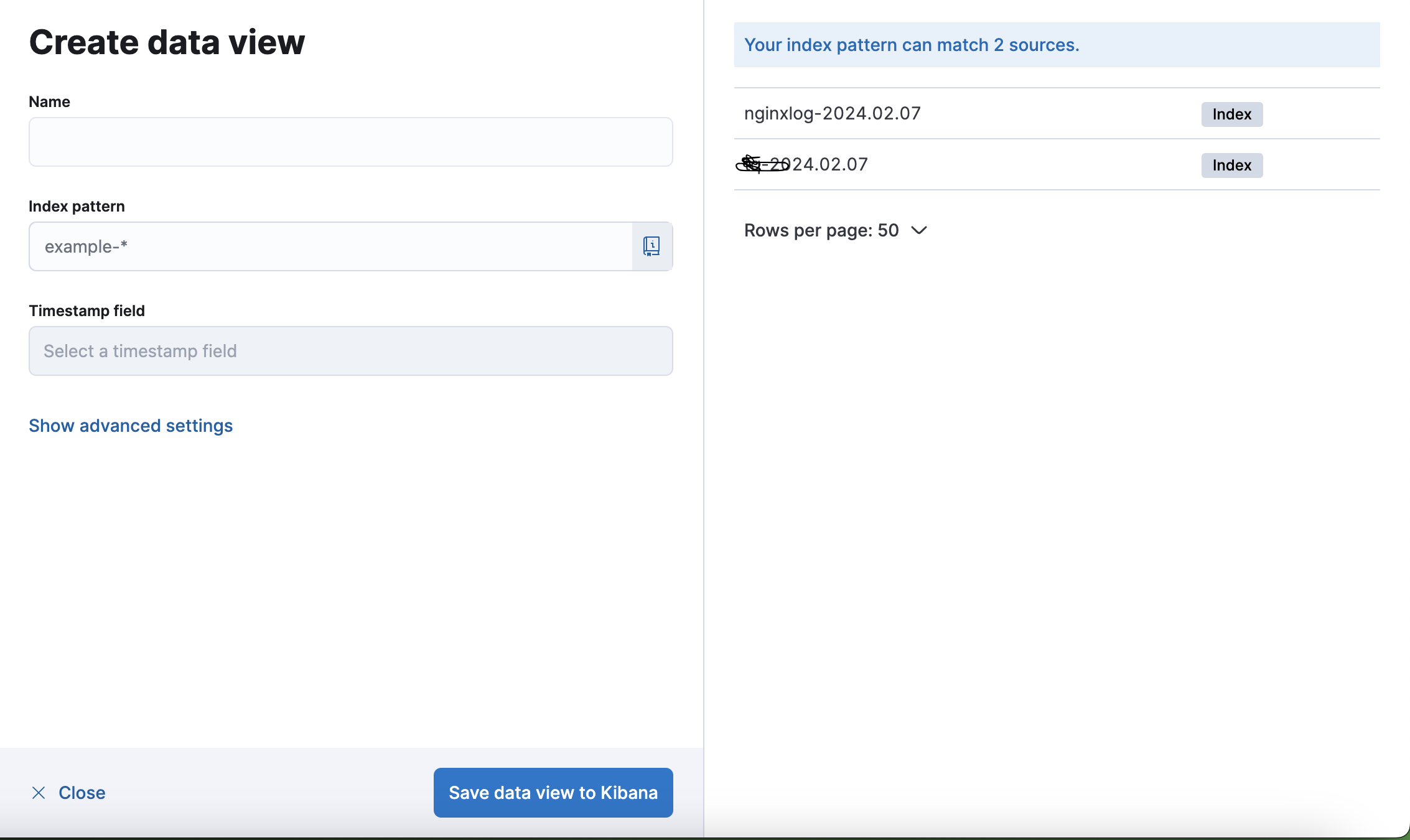
index pattern에 본인이 대쉬보드를 만들기 희망하는 인덱스 이름을 적어주고,(우측에 뜨는 이름을 적어야함, 임의로 적으면X)
그후 이름도 적절하게 지어준후 save data view to kibana를 눌러준다
그후 뜨는 창에서 create a dashboard -> dashboard visualization 을 눌러준다
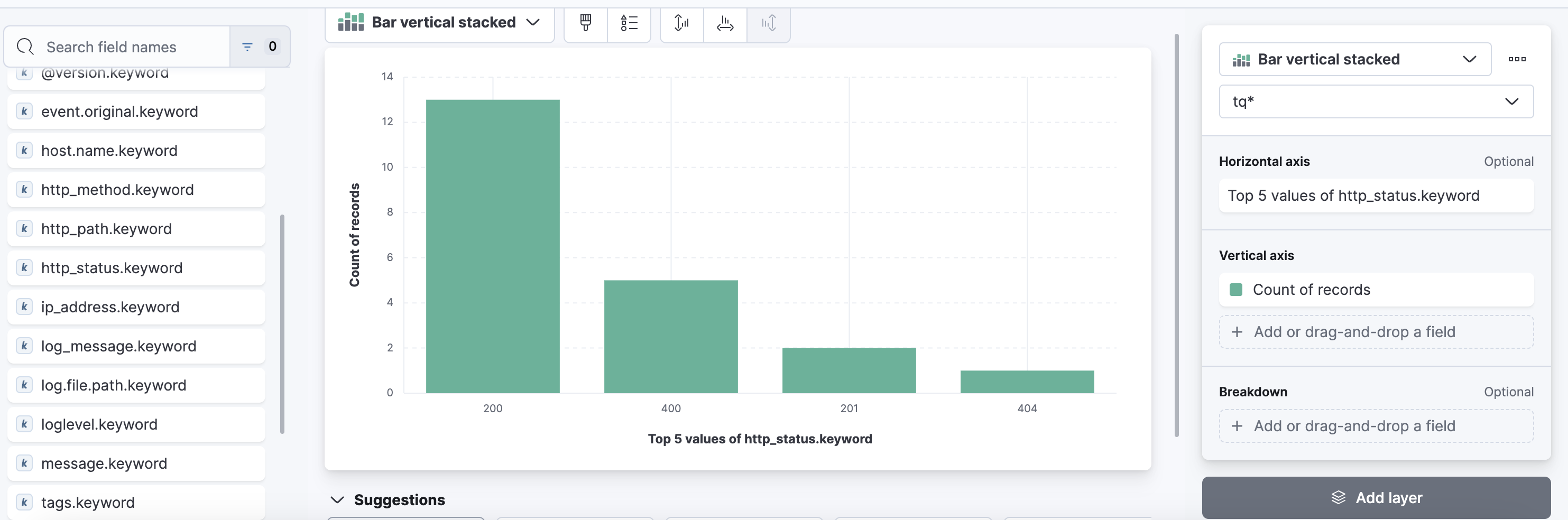
그 후 우측에 보면 내가 설정한 로깅 포멧대로 나열이 되어있는데. 본인이 필요한 정보들을 사용하여 대쉬보드를 만들면 된다.
이 이후는 직관적으로 할 수 있어서 설명을 따로 적어놓지는 않겠습니다.
저같은 경우는 예시로 상태코드들만 볼 수 있도록 해놨습니다.
(글 처음에 위 처럼 설정한 로그 포멧중 상태코드에 해당하는 부분들로 대쉬보드를 만든거임.)
logger.info(f'INFO {client_ip} {current_time} GET /calendars 200 calendar is inquired')logger.warning(f'WARNING {client_ip} {current_time} POST api/v1/diaries//DiriesPost 400 {calendar_serializer.errors}')
좌측에 정보가 부실하다던가, 내가 설정한 정보가 안나온다 하는 문제는 Logstash의 Filter 부분과 내가 정의한 로그 포멧과 일치하지 않아서 그럴 수 있습니다.(네 제가 그랬습니다)