
개요
우당탕탕 환경 설정 과정
EC2인스턴스의 자원 감시를 위해 모니터링 툴이 필요하다고 생각을 했다. AWS가 제공하는 CloudWatch가 있으나, 기존 로그데이터 시각화를 위한 Loki + Grafana 환경과 같이 쓰고 모니터링 서버를 따로 두기 위해 해당 기술을 선택하였다.
1. 서버의 메트릭 데이터를 뽑아야 한다. Node-Exporter를 이용. 하지만 Node-Exporter는 메트릭 데이터를 보여줄 뿐 유지를 하지 않는다.
2. 데이터를 보존하지 않는 Node-Exporter의 특성을 보완하기 위해 Prometheus를 이용해 메트릭 데이터를 보존
3. Prometheus에 쌓인 데이터를 시각화 하기 위해 Grafana이용
환경
- Ubuntu 22.04
- prometheus, version 3.2.0
- node_exporter, version 1.9.0
- grafana version 11.5.2
메트릭데이터 수집과 저장 과정
Docker-compose 및 Config 설정
Monitoring a Linux host with Prometheus, Node Exporter, and Docker Compose | Grafana Cloud documentation
Monitoring a Linux host with Prometheus, Node Exporter, and Docker Compose In this guide, you’ll learn how to run Prometheus and Node Exporter as Docker containers on a Linux machine, with the containers managed by Docker Compose. Docker Compose is a too
grafana.com
프로메테우스의 공식문서이고,
메트릭 수집을 위한 Node-Exporter 메트릭 데이터 저장을 위한 Prometheus를 도커컴포즈환경에서 이용할 수 있도록 해주는 yml 문서가 있어서 그대로 보고 참고를 하고 설정파일도 같이 있어서 내 환경에 맞게 바꾼 후 마운트를 해서 사용하였다.
추가로 설정파일과 도커 컴포즈에 있는 커멘드에 대해 알아보려고 아래 공식문서들을 찾아보았다.
내가 처음에 착각했던것.
위 도커 컴포즈는 Linux환경에서 사용가능한 yml파일이다.
일단 내 개발 환경은 MAC 환경이지만 베포환경은 ubuntu환경이기 때문에 위
도커 컴포즈를 그대로 실행한다고 해도 오류는 안 나오지만 메트릭 정보가 수집이 되지 않았었다.
프로메테우스 커맨드
prometheus | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
프로메테우스 config
Configuration | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
Prometheus를 사용하기 전, Node-exporter와 Prometheus의 관계
Node-exporter
Node-Exporter는 내 컴퓨터에 있는 메트릭정보(CPU, RAM, DISK 사용량 등등)를 수집해 주는 역할을 한다.
수집은 어떤 방식으로 해줄까? 조상님이 해주시나?
공식문서에 Docker-Compose.yml를 살펴보면 볼륨에 아래와 같이 정의되어 있다.
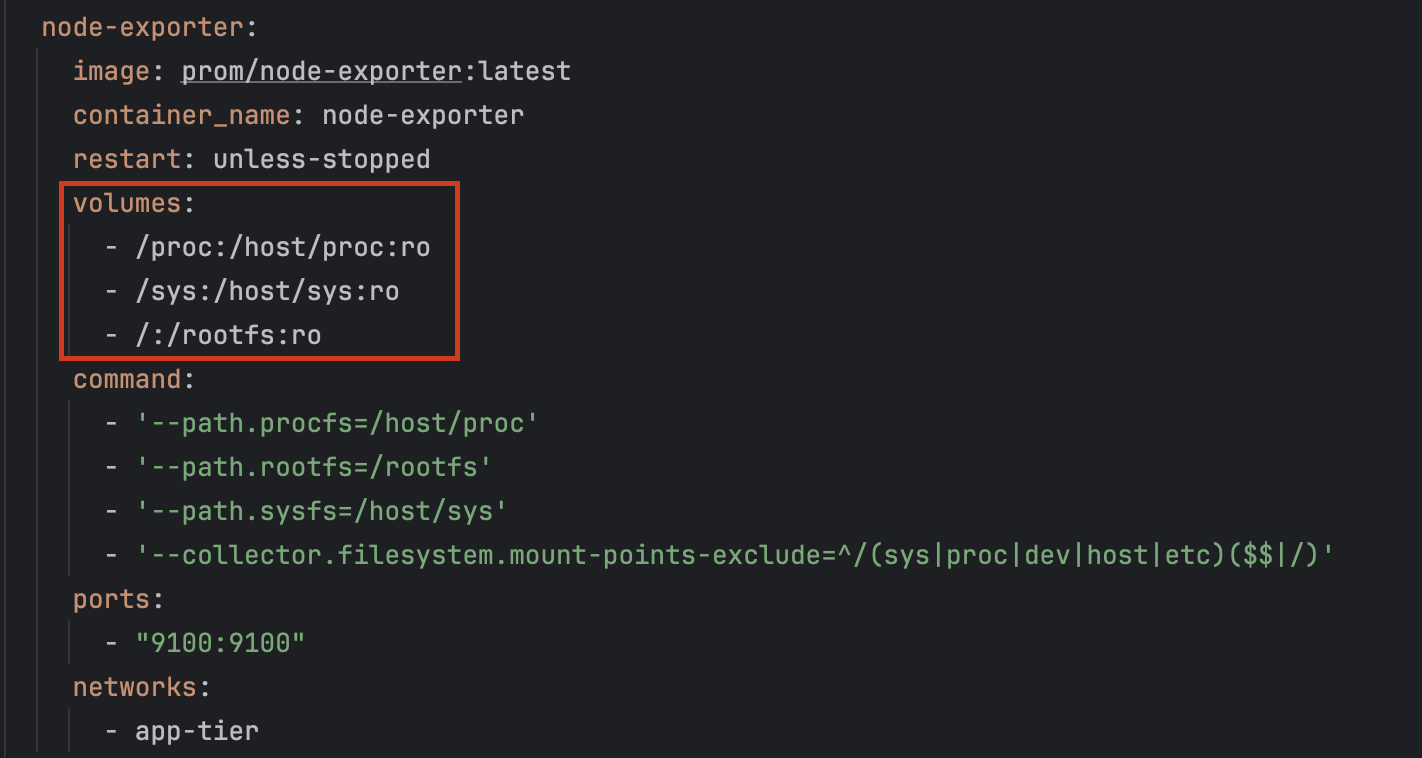
즉 호스트의 /proc , /sys, / 경로를 읽기 전용으로 마운트 해서 해당 부분에서 메트릭을 뽑아오는 것이다.
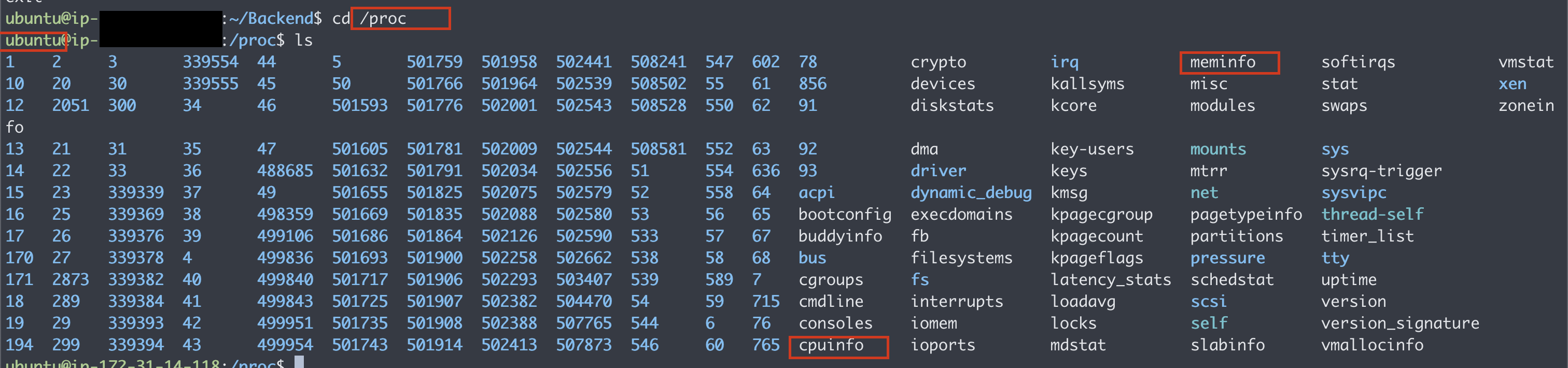
/proc 경로를 가서 ls를 쳐보면 직관적으로 메모리 CPU관련해서 정보가 들어있는 부분을 볼 수 있다.

/sys에 들어가 보면 디스크 관련된 부분, 커널 하이퍼 바이저 등등 운영체제와도 관련이 있어 보인다.
-콜아웃-
호스트 머신의 메트릭 정보가 있는 디렉터리를 Node-Exporter에 마운트를 하면
Node Exporter는 CPU 사용량, 메모리 사용량, 디스크 IO 등 시스템의 중요한 성능 지표들을 Prometheus에 노출한다.
Node Exporter가 제공하는 메트릭은 Prometheus와 같은 도구가 이를 수집하고, 외부에서 시스템의 성능 및 상태를 모니터링할 수 있게 해 준다.
Prometheus
노출을 좋아하는 Node-Exporter는 친절하지 않다, 위에서 언급한 것처럼 메트릭 정보를 노출을 해줄 뿐 가져가는 건 셀프로 가져가야 한다.
처음에 링크를 달아놓은 공식문서에 가면 Prometheus.yml 부분이 존재하는데 해당 파일이 담당하는 부분은.
Node-exporter가 노출한 메트릭 정보를 어디서? 어떻게? 얼마만큼의 간격으로? 가지고 올지 결정하는 역할이다.

초기 세팅은 위처럼 두 개의 Job으로 구성이 되어 있다.
- Prometheus 본인의 메트릭 정보
- Node-Exporter가 노출 한 메트릭 정보
블록의 시작점을 보면 scrape_configs라고 되어있는데 위에서 언급하였듯 Node-exporter가 노출한 메트릭 정보를 우리가 긁어오듯이 수집을 해야 한다고 했다.
Job_name은 추후에 PromQL을 이용해서 메트릭 정보를 시각화할 때 이 메트릭이 어떤 메트릭인 구분하기 위한 이름이고
scrape_inerval은 몇 초의 간격으로 긁어올지 결정하는 부분이다.
target은 Node-Exporter가 메트릭을 노출하는 경로이다.
경로에 Localhost와 node-exporter는 무슨 차이죠?
기본적으로 컨테이너끼리 통신을 할 때는 컨테이너이름:포트 방식을 사용해야 한다.
하지만 prometheus에는 localhost가 붙었는데 이유는 해당 설정파일은 prometheus의 설정파일이다. 즉 본인의 메트릭을 본인이 긁어오려면 컨테이너 간 통신이 아닌 자기 자신과의 통신이기 때문에 localhost를 사용하는 것이다.
🌅 Granfana 연동
Grafana로 시각화를 해보자
Run Grafana Docker image | Grafana documentation
Run Grafana Docker image You can use Grafana Cloud to avoid installing, maintaining, and scaling your own instance of Grafana. Create a free account to get started, which includes free forever access to 10k metrics, 50GB logs, 50GB traces, 500VUh k6 testin
grafana.com
기존에 Loki + Grafana를 사용하고 있어서 공식문서에 있는 설정을 그대로 쓰지 않았지만, 혹시 몰라서 밀고 테스트 했는데 잘 되니까 그대로 해도 될 듯하다.
그라파나는 시각화 도구이다.
시각화를 하기 위해서는 데이터가 있어야 시각화를 할 수 있는데 데이터 소스를 어떻게 가지고 올 것이냐.
즉 Prometheus와 연동을 어떻게 할 것인가. 에 대한
방법은 두 가지가 있다.
방법 1. Grafana에 접속해서 수동으로 연동하기



문제: Connection 부분에 url을 어떻게 입력을 해야 할까요?
위에서도 같은 네트워크에 있는 컨테이너 간 통신은 Localhost가 아닌 컨테이너이름:포트 형식으로 지정을 해야 한다고 언급을 했었는데

그라파나 컨테이너가 프로메테우스 컨테이너로부터 데이터를 가지고 와야 하기 때문에,
http://prometheus:9090으로 입력을 해주어야 합니다.
다만 도커 환경이 아닌 직접 컴퓨터에 그라파나 프로메테우스를 직접 설치해서 쓴다면 http://localhost:9090이 되겠죠?
방법 2. 쉘 스크립트를 이용해서 데이터 소스 연동


🌠 시각화
PromQL
무엇을 시각화해야 하지?
내가 생각한 건
- 메모리의 평균사용량, 가용 가능한 메모리 용량, 사용 중인 용량
- CPU의 평균 사용량
- DISK의 가용용량 및 루트 파티션의 가용용량
함축하면 이 정도다!
시각화를 해보자



node_라고 검색했을 때 나오는 부분이 Node-Exporter가 수집한 메드릭 정보에 대한 것이다.
prometheus_라고 검색했을 때 나오는 부분은 프로메테우스 본인의 메트릭 정보이다.
DISK 시각화


디스크를 전부 조회해 보면 마운트 포인트가 여러 가지인걸 볼 수 있다. 그중 나는.
루트 파티션 모니터링(MountPoint="/")
루트 파티션은 사용자의 입장에서 파일을 저장하고 예를 들면 게임도 설치하고 영화도 다운로드하고 하는 공간이다.
안 쓰는 도커 이미지들 혹은 캐시들을 정리를 해보면 GB단위는 우습다. 모니터링 툴을 달기 전에 루트파티션의 용량이 부족했던 적이 있었다.
하지만 해당 정보를 모니터링하면 사전에 감지할 수 있다고 판단하였다.
추후에 업데이트를 해야 하는데 용량이 부족해서 중간에 끊기는 일을 방지하기 위함이다.
node_filesystem_avail_bytes{mountpoint="/"}/1024/1024/1024node_filesystem_size_bytes{mountpoint="/"}/1024/1024/1024node_filesystem_size_bytes{mountpoint="/"}/1024/1024/1024 - node_filesystem_avail_bytes{mountpoint="/"}/1024/1024/1024sum(node_filesystem_avail_bytes)/1024/1024/1024sum(node_filesystem_size_bytes)/1024/1024/1024
"/run"
프로세스가 실행 중일 때, 프로세스의 PID가 /run에 저장.
이 디렉터리는 일반적으로 프로세스가 실행되는 동안에만 존재하고, 재부팅을 하면 자동으로 초기화가 된다!
"/run/lock"
예를 들어, 두 개의 프로세스가 동시에 같은 디바이스 파일을 열려고 할 때, 첫 번째 프로세스가 잠금을 설정하고, 두 번째 프로세스는 잠금이 해제될 때까지 기다리게 됩니다. 이때 잠금 파일이 /run/lock 디렉터리 내에 생성됩니다.
"/boot" "/boot/efi"
시스템 부팅에 필요한 정적 파일들이 들어 있다, 현제로써는 배제하였다.
Memeory 시각화
전체 메모리 사용량

rate(node_memory_MemTotal_bytes[5m])/1024/1024/1024 - rate(node_memory_MemAvailable_bytes[5m])/1024/1024/1024node_memory_MemTotal_bytes/1024/1024/1024node_memory_MemAvailable_bytes/1024/1024/1024node_memory_MemTotal_bytes/1024/1024/1024 - node_memory_MemAvailable_bytes/1024/1024/1024
Swap메모리 사용 현황

node_memory_SwapTotal_bytes - node_memory_SwapFree_bytes100 * (node_memory_SwapTotal_bytes - node_memory_SwapFree_bytes) / node_memory_SwapTotal_bytes
스왑메모리는 메모리의 사용용량이 일정 수준을 넘어갈 시 디스크의 일부를 메모리처럼 사용하는 곳이다.
예전에 윈도 그램을 사용했을 때 도커 컨테이너를 여러 개 띄우고 사용했었는데. 그 당시 노트북의 메모리 사양이 안 좋아 스왑 메모리가 많이 사용되었었다.
그래서 C드라이브가 항상 빨간색으로 떴던 기억이 있어서 추가하였다.
Cache메모리 사용 현황

해당 캐시 메모리는 OS캐시 메모리이다. CPU에 있는 그 캐시와는 다르다.
OS캐시는 디스크에 있는 파일 등, 정적 파일을 들 필요에 따라 캐시를 해놓는데.
68%인데 너무 높은 거 아니에요?
해당 값은 비는 메모리 공간에서 유동적으로 사용하다가, 캐시 외적으로 메모리를 사용해야 할 때. 동적으로 할당 해제를 해주기 때문에 따로 신경을 쓸 필요는 없지만. CPU의 캐시와 잠깐 혼동을 했어서 적어봤습니다
오히려 해당 값이 높으면 디스크에 대한 접근을 최소한으로 하고 캐시에 있는 데이터를 잘 쓰고 있다는 지표로 참고할 수도 있습니다.
node_memory_Cached_bytes / node_memory_MemTotal_bytes * 100CPU 시각화

전체 CPU 사용량

(1 - avg(rate(node_cpu_seconds_total{mode="idle"}[5m])))*100
전체 CPU 용량에서 "idle" 즉 놀고 있는 애들은 빼고 남은 값들이다.
커널과 애플리케이션에서의 CPU사용률 비교

"System과 User가 있는데 각각 무엇일까?"
System은 커널 애플리케이션이 사용하고 있는 CPU의 비율이고
User는 커널 애플리케이션을 제외 한 나머지 애플리케이션이 사용하는 비율이다.
커널 애플리케이션은 하드웨어 자원 관리에 대한 것들이 주로 있겠다. 해당 값이 높다면,
많은 네트워크 트래픽 처리 혹은 I/O작업들이 많이 밀리고, 콘텍스트 스위칭이 많이 일어난다는 말로 해석할 수도 있겠다!
유저 애플리케이션은, VsCode, MySQL, 혹은 게임 등이 될 수 있겠다. 즉 어플리케이션 서버에서 부하가 많이 일어나고 있다는 지표로 해석할 수도 있겠다!
sum by (mode) (rate(node_cpu_seconds_total{mode=~"user|system"}[5m])) * 100
I/O 대기시간
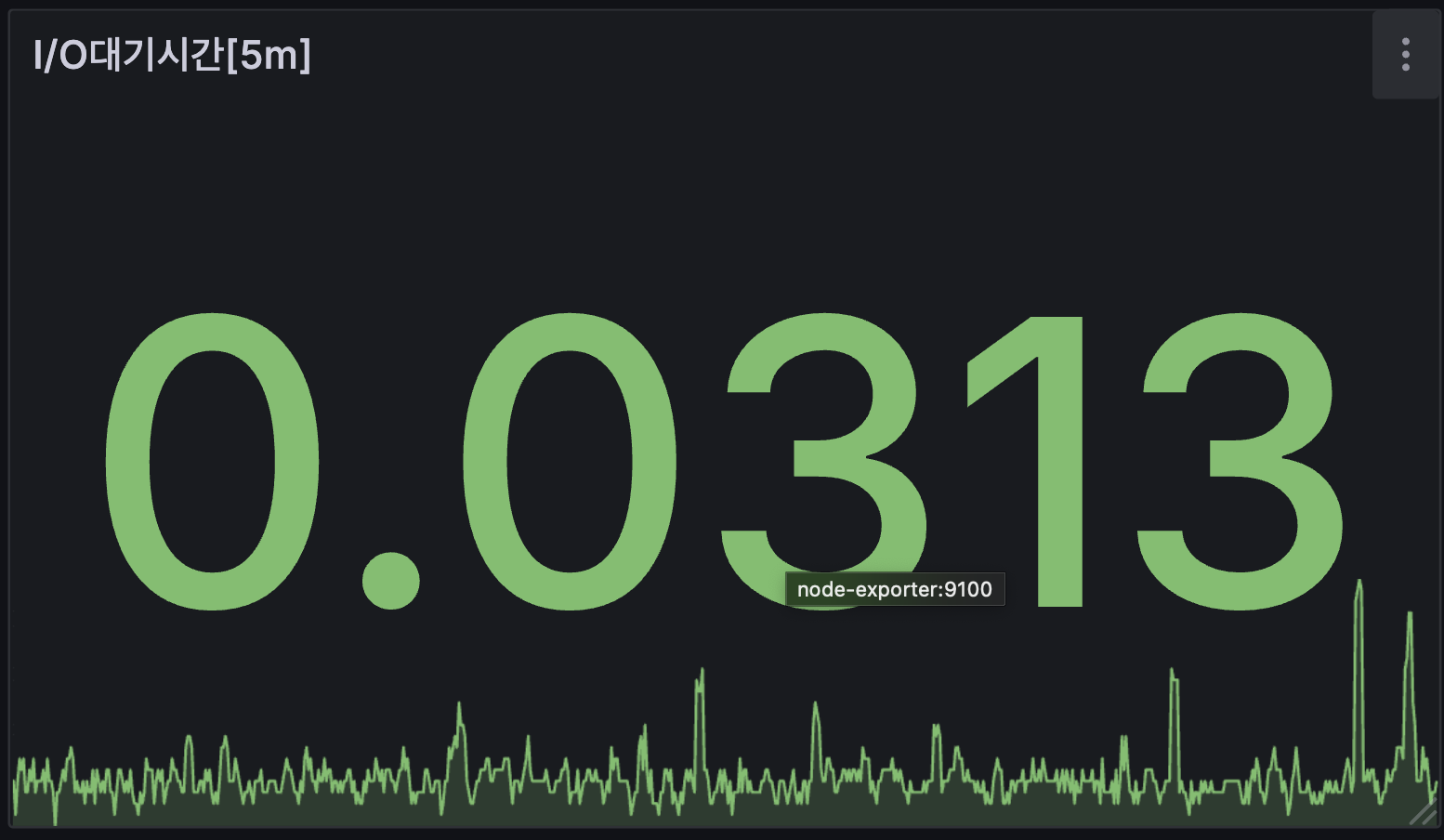
I/O대기시간은 CPU가 열심히 일을 하다 필요한 데이터가 있어서 해당 값을 기다리는 시간이다.
박스 포장 알바를 하는 도중
나 : (열심히 박스 포장 중)
나 : 다 했어 다음 박스 줘, 어 바로 옆에 있네 OK
해당 박스를 다 포장하고 다음 박스를 기다림. 옆사람이 바로바로 줘서, 옆 사람이 박스를 건네주는 딜레이가 짦다 I/O 가 짦다
나: 어이 김형! 테이프 다 떨어졌어
김형 : 테이프 사무실에 있는데 기다려봐.
나: 아. 바쁜데 얼마나 기다려야 해 거참...

해당 상황은 내가 일을 하는 도중 테이프가 필요해 김형이 사무실에 들러서 가져다주는 상황인데. 이 경우는 I/O가 높은 경우라고 볼 수 있겠다.
즉 이 경우는 뭔가 딜레이가 걸린다는 이야기이다, CPU가 작업을 하기 위해 필요한 데이터가 늦게 오는 경우인데, 네트워크 응답 지연 및 디스크 읽기 쓰기 문제로 늘어날 수 있다.
avg by (instance) (rate(node_cpu_seconds_total{mode="iowait"}[5m])) * 100
네트워크 트래픽


rate(node_network_transmit_bytes_total{device="eth0"}[3m])